读ZERO的内容总是让人陷入深思,本篇文章是ZERO发表在知乎(https://zhuanlan.zhihu.com/p/3637411399)。复制这篇文章是为了保存并做一些个人解读。
距离我写的上一篇SEO文章已经一年多,各式各样的原因以致未来应该也不会写多少SEO相关的文章了,也有可能这就是最后一篇。但越是如此,我就会想把它写的越系统、越深入,即便SEO从业者已经不多,剩下大多也看不懂本文。但十多年的职业生涯,既然懒得写一本书来汇总,那多少还是该留下些许真正有意义的东西,无论此中的意义到底有几人能切实体会。
本文要讲述的,是自从我在2012~13年任赶集SEO负责人期间,至少在某些层面上已站在整个SEO行业的天花板后,再往后的十多年里面,踏入完全无人涉足的领域走了究竟多远的距离。比以往所有文章会更深入的说明理论研究的方法——正是那最没人爱看,却也最关键的地方。
我智商125左右,这意味着国内大约十来人里面就会有一个这般聪明程度的,像是在互联网大厂里面,我这点智商很可能都够不到平均线。
我从十几岁开始就患有抑郁症,即便情绪良好且稳定,但极度的嗜睡。前两三年终于改善之前,在大半个职业生涯之中,我每天要睡十一二个小时,剩下的时间也大多处于昏昏欲睡的状态。
大学只读了一年就肄业,并非学霸不屑于学习,而是学渣反正不主动退学也可能会被劝退。勉强考进一个二本大学也只能垫底,工作后在各个基础学科上也几乎再无额外学习,毫不夸张的讲就只有高中文化水平。
努力和天赋都不足,剩下来说机遇成分的话,这肯定是有——21岁的时候,赶集网的CEO杨浩涌正是在知乎上面留意到我并把我挖去,这无疑加快了我几年的进度。
然而他之所以会让我担此重任,也是因为我此前已经有足够多的独到研究——比如我做SEO的头一年,狼雨把「SEO」这个词的排名做到百度首页,当时行业里面很多人都在研究他怎么做到的,却也没人能效仿,但我那时就已经知道,而且几年后我在美团任职太闲的那阵也确实把这词的排名给搞了上去。再如做SEO的第二年,碰上Google Panda算法更新,那一批大小外贸网站几乎全挂了,没见有哪个恢复的,然而我也很快就轻松定位到了其降权所识别的特征。
离开赶集网之后,运气这个东西也离我越来越远,但不妨碍我越来越轻松做出SEO效果。
当然我不认为自己如今有做到什么样的高度。就我这种理论研究水平,尤其和科研工作者比较起来,简直就是贻笑大方。在SEO这种低门槛行业做到天花板,稍微有点像是在专科学校考到全校第一,终究也只是比上不足比下有余的程度。但是,既不够聪明更不够努力的诸多前提下,也已经可达到的程度理应至少有多高,这是我想在文中体现出来的。
有许许多多聪明而又努力的人,他们本应是十倍百倍的强于我的,而事实有时却还相反。在我看来,这是对他们与生俱来天赋的极度浪费。
搜索引擎的机制是一个黑盒。
业已掌握的信息极为有限的前提下,想要探明一个极为庞杂的系统,这从根本上来讲就是毫无可能的事情。
我听无数SEO从业者都说过,做百度就那么些东西,没什么复杂的。反倒是我从来不会那么说,同时也知道,自己对百度知之甚少。
反向解析一个系统,一定是比正向设计一个系统更困难上至少一个量级的,SEO天生就是一件比研发搜索引擎还艰难得多的事情。只不过,恰好搜索结果的第一页总是十个排名位置,但凡另外9个选手差到极致,那么自己只要差得没那么离谱也能相对而言的排在第1位,倒也同样拥有最大化的流量效果。
即便如此也从不意味着,我们只需要做到比所有竞争对手都强上那么一点就够了——着手优化一个网站,是忙活两周就足够做到行业第一,还是花上两年功夫才能达到,这之间又是天壤之别。
个人解读:普通人的时间和资源有限,验证一个seo的知识点耗费的成本是很难计算的。
一切背后都是概率
尽管全面掌握搜索引擎的规则是绝无可能的,但我们仍旧有机会逐步的去掌握一个一个的操作点,逐步的构建起成熟的流程;并且当掌握的有效操作点足够多了之后,也有机会将它们之间编织成网状,形成一个完整的体系。只不过我们必须意识到,无论是零散的操作点,还是更完整的流程体系,其中没有任何一处的细节是我们可以完全确定的,归根结底也只能是说对各个知识点上有多大概率的把握。
个人解读:搜索引擎排名,更多的感受是做正确的事情,少犯错,页面已经很复杂时做减法,页面过于简单时做加法。
有些时候,我们可能只有六七成的把握。比如一些实现成本很低,且不太可能带来负面效果的改动,在实际项目落实的时候往往就不应该绞尽脑汁去想如何进一步验证它们是否有效,而是该闭着眼睛向网站上面去做——就算一两件这样的操作能不能带来流量效果还很难说,但一二十件这样的改动,总有几项切实有用的,这种方式可以很稳定的带来流量增长。当然前提还是,这只适用于技术、产品等方面落实成本都很低的改动。
再有些时候,有九成把握,那么很多时候也够了,即便假设这改动的实现成本刚好比较大,往往也值得去做。做一件没有绝对把握的改动,其性价比通常都高于继续在理论研究上面钻脚尖,毕竟后者太容易平白的耗费时间。
继续往深入来讲,哪怕我们通过AB测试来得到了极为明确的结论,其实在根本上我们也绝无法100%确定结论的正确性:AB测试的样本很少的时候,统计误差会比较大,自然会难以得到明确结论;而随着样本数量的增加,我们对于结论有效的把握最终可以无限趋近于100%,但也只能是类似99.99999%这样的。AB测试只是对零散个例的效果变化的整体归纳,而归纳法是或然的,它无法得到必然性的结论。
单纯从AB测试的角度来看,追究99.99999%和100%有什么区别,好像有点小题大做了。但讨论这一点会有利于我们更深切的认识到,一切的背后都是概率。
一定要做出区分的是,我前面提到的,都是在具有「客观可量化」的把握程度时才应该去做的事情。诸如「有九成的把握」这自然不是指的我们主观感觉上的多半能行。SEO行业最大的通病之一,就是感觉某项操作可能有效果,就去试一试——试到后面十回里面九个黄,剩下一个不尴不尬,最后公司里面产品技术都不愿意配合继续折腾,却反过来埋怨产品技术对SEO的支持力度不够。
在公司环境里面,会看到很多其它部门其它组的同事都是这么做的——多试一试,比不试来得强。很多领域没那么多规则,于是他们是可以这么做,往往只要运气稍微好一点就能收获可观效果。但SEO可不能这么学,面向搜索引擎此般庞大的混沌系统,也想随便试一试就撞上好运,那需要的运气可远不止是一点半点了。
对于概率的量化
也不知道为什么,2019年前后有挺长一阵时间,整个行业风靡着阅读百度专利的做法,认为这是最顶尖的技术。百度专利是一个不错的信息获取来源,行业头部的小圈子在2013~14左右就开始集中挖掘各种专利了,它们从丰富常识的角度来讲颇有助益。但哪怕读了再多艰难生涩的专利,其实根本无法帮助自身脱离SEO的入门阶段。
无论是搜索引擎原理书籍、早年的百度搜索研发部博客、如今的百度Geek说、百度专利等等,都是很好的底层知识的学习渠道,其中也有一部分的重要性几乎可以说是必不可少。但除了帮我们建立更全面的常识以外,这些资料不会直接告诉我们哪些操作会是真正有效的,接下来想要验证的话,那还是只能回到前面的方法,也就是不断试一试。
即便不去折腾公司里面的产品技术,而是拿自己手头的网站来不断测试,能解决的问题也很有限。因为倘若的确去细致阅读了足够多的资料,再汇总去深入去思考的话会发现,可以发散出去的潜在可能性实在太多太多了。
一种典型问题是,学术界研究的以及专利里面维护权益的那些东西,很多是不会在工业界落地的。
进一步还有个更普遍的问题是,很多策略在线上确实存在,但它们对流量效果的直接影响却也很小,其实并不值得关注。
假如手里有一个长尾流量很大的网站(也即意味着足以消除统计误差),自己又擅长技术,那么同时做几十上百组AB测试,此时这种看资料再多试一试的方法也是一定程度上可行的,花上几个月时间至少足以站在SEO行业的TOP1%;不过真没什么必要这么去做,倘若都已经具备这些先决条件了,完全没必要采用这种笨方法。
要追溯本质的话,核心问题还是在于,任何资料都没法直接告诉我们这些操作有效的概率有多大,以及到底多有效。
想要直接知道各个操作有效的概率有多大,以及到底多有效,这事完全是可行的,只不过必须把过去的做法给完全反过来:通过观察实际排序结果,去倒推其背后的成因。
根本上也即反向推理。反向推理的基本范式是穆勒五法,毕竟是逻辑学里面的纯理论性的东西,这里不多赘述,但它一定是后续所有研究最核心的东西。
个人解读:比较佩服的是zero的反向推理中关于构建这个模型的能力,如何抓取和分析,如何去针对自己的目的构建流程,这个无论是技术还是心理上我都不能做到。
仅说说穆勒五法再结合些基础统计学方法,一种最简单的应用场景:
统计行业内在某项排名指标上表现最好的网站,将它们的主要着陆页汇总罗列出来。
它们的共性之一,即排名好;那么进一步显然该去找排名好这个结果背后,有没有什么共同的成因。
假设一共有10个被分析的网站,其中,发现8个网站上都存在面包屑导航。同时,统计所有行业网站,发现只有30%的网站上面带有面包屑导航。
『在特定的10个对象之间,其中有至少8个出现了某一现象。与此同时,在所有对象之中,该现象的出现率为30%。假如那选定的10个对象是随机分布于所有对象的,和该现象之间毫无必然关联,那么「在特定的10个对象之间,其中有至少8个出现了某一现象」的自然发生概率是多少?』
这是一道典型的统计题,计算二项分布概率。显然我一沓糊涂的数学水平掌握不了二项分布公式这种非直觉性的东西,但任何人应该都可以和我一样,通过与直觉完全相符的思路去写一段简单的Python代码来暴力求解:

这个数字意味着,如果面包屑导航与排名无关,那么我们恰好看到10个网站里面至少有8个存在面包屑导航的几率大约是0.16%
那同时也就可以反过来说,我们有99%以上的把握可以确定:面包屑导航一定与排名高有关(要么它能直接使得排名变高,要么它和其他使排名变高的因素之间存在非常紧密的联系)。
进一步的,假如这10个网站里面,同样有8个网页,都在h1标签中包含了关键词;与此同时,所有网站之间有40%的比例存在这个现象。
那么可以类似的,计算得到其自然发生概率大约是1.23%,也极有可能和排名高有关。
关键是,在这样的假设背景下,对比这两个概率数字还可以得出另一条结论:网页存在面包屑导航,和h1标签包含关键词之间,前者和排名的联系更大。
通过这样的形式,就已经初步量化出了「这些操作有效的概率有多大,以及到底多有效」。
面包屑导航,和h1标签包含关键词这两个纯属举例,它们对排名都有帮助,但都远没有这么大。在实际场景中,当然比这个最简化的示例要复杂得多,比如首当其冲的问题就是,大多类型的行业里面表现足够好的网站数量很有限,连10个都凑不足,这时统计误差过于大。合理的方式就是通过全网所有行业的网站来分析。
于是此处有个不算太小的最低技术门槛——先抓至少数以万计的关键词排名结果,再抓取数量还要大一两个量级的各网站着陆页的HTML源码。
但如果被技术卡脖子,这是不应该的。诚然程序技术的天花板极高,诸如AI模型的研发也是技术领域的事情,我不是在讨论一定要做到那种地步。不过,我始终认为对于一个SEO从业者而言,至少至少技术能力也得做到可以非常轻松的由框架从零开发一个中型网站的程度(显然比博客、问答网站更复杂, 大约相当于电影站、B2B等类型的开发难度,但不需要到在线工具、电商等强交互类型网站的水平)。
程序技术的入门乃至到稍微进阶的阶段,做的事情无非是一个把各种功能像搭积木一样搭起来的过程,即便这些积木表面看上去奇形怪状,也不过是有个额外学习成本。实际把它们搭起来的过程中基本都不需要动脑子——至少和逻辑学和数据分析这些比较起来是这样。
倘若这都做不到的话,那么会发现无论是更进一步的程序技术本身,还是搜索原理、数据分析、逻辑推理等等方面,相较之下都要更难以着手得多。
个人解读:深有同感
不过,归根结底这些东西其实也不难,毕竟连我都能掌握。稍微不一样的地方是,我是用了十多年的时间来逐渐学习这些的,而SEO行业里面的哪怕已经做了十多年的,其中多数人连这些东西的边都没去触碰过。
机器学习产出规则的时代
诸如国外的SEOMoz在2011年左右组织用Pearson相关系数(后来改为用Spearman)这样的统计手段来研究排序因素,很难谈得上是走在正确路上的,毕竟统计相关性和实际因果性之间有着过远的距离,没法直接的得到任何有效结论,到头来还是得靠试一试才行,于是我不把这种看做SEO研究应该要走的路径。由此,前面例子中,穆勒五法加上统计手段的应用,应该算是真正的SEO工作之中已经最最简单的部分。
即便我如今做的足够系统化,因此也从相对比较系统的角度来阐述它,但是在2013年的时候就已经全面在使用这些推理方法。当时我只有两三年SEO经验,却可以做到单枪匹马的把赶集网SEO流量逐步压过58同城的一整个团队,就是依赖的这种在研究途径上的绝对优势。
刚才的例子之中,是通过手动观察案例网站之间的共性,然后提出「面包屑导航对排名有助」这样的假说,再去通过概率来验证它。可以通过二项分布或程序暴力求解来把概率的数值直接给计算出来,这是一个非常理想化的场景,到了更往后的研究就很难用上了。
在召回->粗排->精排这个漏斗模型的靠末端的部分,搜索引擎实际看的排序特征数量会急剧增加。哪怕特别早期的搜索引擎,众所周知也至少有几十个排序因素在共同作用,此时绝无可能像召回环节那样有机会通过一两个假说去解释所有的现象,推理难度开始指数级增加。
除了「提出假说」这个步骤会困难得多以外,「验证假说」这个步骤也会开始明显受阻。
区别于前面假设了一个面包屑导航的例子,这边讲述一个真实的例子(因为百度目前已经砍掉了这项规则):
统计海量数据,观察到「备案」这两个字和排名表现好之间呈现出明显的相关性,此时,实际可能性有二:
- 只要网页上有「备案」两个字,排名就能得到提升
- 因为写了「备案」两个字的通常都是确有备案的正规运作网站,根本上只是因为这些正规网站自身质量出色而导致了数据上的相关性
(注意:大部分确有备案的网站也是没有「备案」二字的,它们通常只写了诸如「京ICP备12345678号」)
下一步确定因果关系,其中一种最常见的方式是去控制与「备案」二字存在紧密关联的变量。此例中,应当找出实际没有备案,但也写了「备案」二字的网站(比如会存在曾有备案而后来被注销了,但网站上的这几个字暂未去除的),横向对比其它没有备案的网站,看前者排名是否依旧占优。
需要根据每项特征的具体情况不同,去选择不同的控制变量的方法。
但实际情况中,分析数以万计的域名在当下时刻的备案状态,也不是一件特别轻松的事情,所以控制变量的方式在此例中不是一个最优选择。
这边先说下结论:至少在大约2020~2022期间,百度上确实存在着这样一个荒唐的规则。无论网站自身是否有备案,只要在页脚上面写上「备案」二字就能极大幅提升——毕竟这个规则看上去太离谱了,而且单纯使用推理手段在理论上必然无法排除掉有盲区被遗漏的可能性,我就仍谨慎起见的做了AB测试,在我一个没有备案的每日有数万UV的网站上面如此操作,测试组流量得到了数十百分点的提升。
在AB测试之前,我之所以已对这项操作很有把握的原因倒也简单,直接跳过了进一步的数据统计:因为已有统计数据中,「备案」二字和排名表现之间的相关性实在太强了,极难想象只是网站备案与未备案的排名差距可以如此之大,这和过去多年经验全都不符。
自己过去多年的大量相关经验恰好全部有误,又或者,百度就是恰好有那么一个极不合理的规则,就看这两者之间的概率孰高孰低。
文章前面所提到的「概率」主要指的是基于频率的概率,诸如100次试验之中会看到多少次特定事件,它是一种对于概率最直观的理解方式。而后面则更接近于是贝叶斯概率,它需要引入事先具有的经验与后续观察到的现象,去动态的调整对于结论的信任程度。
倘若百度的规则全是人工制定的,那么制定出「备案」二字可以极大幅提升排名这种规则的人非蠢即坏,而且在一个大公司里面这么做还得不被其它人所发现。这种可能性,怎么想也比我过去大量经验全部有误的概率还要低。
真要是这种情况,哪怕我前面计算出数据的过程检验过再多次数,过去项目经验再多,我也只能质问自己是不是已经蠢到了哪怕自己心中最牢靠的东西其实也是错的。因为不然的话就是百度的那群人全比我蠢,那我只该在自己身上找问题。
但百度的规则很多都是机器学习规则来制定出来的,其实它很容易出现问题:只要看到哪些特征经常出现在优质网站上,就容易误以为只要有这些特征的就是优质网站——毕竟只要没有任何人会发现「备案」二字可以额外提升排名,那么预测过程就不会受到干扰,此时通过「备案」二字来预测网站是否优质就还算是合理的方法。
基于机器学习这种天生存在容易混淆相关性和因果性的缺陷,而且它又是个黑盒,其产出的具体规则逻辑哪怕研发者也是无法直接看到的。于是只要百度那儿稍有不慎就完全可能导致「备案」这种奇怪的有效特征。那这种可能性,无疑就比我过去大量经验全部有误的概率要高得多。
和前文的例子里面,判断两个因素之间的相对重要程度所类似的,这里也是横向对比两个概率之间的高低。
其实,大概两三年前也有很长一阵百科站特别盛行,在根本上也是一模一样的道理。机器学习搞不清楚因果性,而百度研发又实在是不动脑子,把全网排名独一档的百度百科也给作为常规样本给灌到训练数据之中了。我当时做了组AB测试,甚至其它什么都没改,只是在title里面加上了一个后缀「_百科」,测试组就已经提升了50%的流量。后来因为这规则过于被滥用(但估计极少有人想明白其中原理),百度也终究砍掉了这东西。
那时候,很多人也都已经看到了百科站极为强势的排名,但又觉得单独去做一套百科页面的成本过大,就不了了之,殊不知其实只要在页面里面随便塞上几处「百科」这词就能大大领先于其它所有尚未发现这一点的竞争对手,可惜得很。
而前面的机器学习规则导致「备案」二字可以直接提升排名这一例,背后所必须的背景知识就是机器学习方面的了解,也即相对比较深入的程序技术上面的知识,这已经开始明显的超出开发个中型网站对应的那些技术能力了。
我最早做机器学习是2012年的时候,由于赶集网每日有几十万的发帖,其中大部分质量很低,会浪费爬虫抓取资源,就尝试用贝叶斯过滤器来事先判断赶集网上面的帖子是否具有得到SEO流量的潜力;尽管当年这个东西最后没有实际落地,但其判断准确率相当高。
了解输入、输出与神经网络的拟合方式,明白常规机器学习实际是用归纳法去做预测。知道很多场景下并不需要搞明白相关联系还是因果联系也足够做出准确预测,才能进一步知道机器学习容易在相关性及因果性的判断方面有怎样缺陷。在实际做过机器学习,在这些背景知识都有了之后,才能确保做出前例的有效推理。
AI大语言模型的时代
「备案」这种个的是几年前还存在的有效排序特征,也不算间隔太远。这两三年内百度的排序极度依赖于其自身的AI大语言模型,它本质上仍完全属于传统机器学习的延伸,只是深度广度不可同日而语。
比如「番茄炒蛋怎么做」这样的query背后,倘若对应的文章标题里面写上「美味」、「好吃」等词,会对排名有非常大的帮助。
与此同时,2023年左右有一小段时期,可以发现「seo怎么做」这样一个词背后,排名好的文章里面经常标题写法是诸如「SEO如何做好」、「教你怎么做好SEO优化」,其特征是「做」字后面还会跟上「好」这样一个字。
某道菜是否「美味」,这是个褒义形容词,会吸引用户点击,对排名有助合情合理。而「做好」和「做」之间的差异只是用语习惯的差别而已,完全不该影响排名。
倘若没有AI模型方面的背景知识,就算看到排名前十的结果里面有四五个都写了「做好」,也基本只能认为这个现象纯属巧合,根本不会想着再去看全量文章里面这种特征占比多少,再去算算二项分布概率。毕竟很难想象知识面和推理能力都全面超过人类的AI模型,竟可以笨到这种地步。
但是如果知道词向量,加上自行训练过AI模型,有观察过模型在训练过程之中的阶段学习结果,就会知道在训练中间阶段loss尚未完全收敛就临时拿出来先凑合用的AI大语言模型,也一样很容易会把两个字面上看上去性质相似的词,误以为它们真的性质相似。
我开始训练AI模型,是2023年初的时候。因为百度规则已经全面转向了AI大语言模型,在末端的精排阶段,AI模型参与非常之多。就如前面提到的「番茄炒蛋怎么做」这一例,其优化方法应该是修改文章,在标题里面加上「美味」、「好吃」等词。
而且随着百度的AI模型逐步完善,规则也在不断更加细化,如今「番茄炒蛋怎么做」这样的词,伴随着「滑嫩」、「鲜嫩」此类词会给它带去更大的助益。
个人解读:深刻理解搜索用户背后的意图,那么找番茄炒蛋制作方式的人,初衷一定是要做一道美味的番茄炒蛋,那么这个搜索结果中,关于做得美味好吃应该是加分项,这个逻辑没毛病!
第二点,如果用户看到做得美味好吃的标题,点击率远远大于了其他标题的网站页面,那么它的排名不断升高也是必然事件。
这些是完全和具体query挂钩的,非通用的特征,不可能再通过人工逐步的反向推理方法来分析——反向推理根本使用的是归纳法,而归纳的前提是有足够多的对象可分析,这在搜索引擎的规则细到一定粒度之后就不可能再行得通了。
AI模型掌握的规则之冗杂是人类不可能触达的,恐怕理论上唯一的解决方案,就是自行训练一个AI模型,让它去掌握百度的AI模型之间的各种细节。
由于很多排序规则是在线环节的,对于时效性要求很高,只能用规模很小的模型;哪怕离线环节的规则,限于计算量非常庞大,百度也依然用不了太大的模型。所以理论上完全有机会用稍微大一些的中等程度模型来学习到百度线上模型的大部分细节。
以上这些是我当时开始自行训练AI模型的缘由。后续在大体上,先训练了一个评分模型用于掌握什么样的内容特征会造成排名位置更高,接下来,再训练应用模型:诸如给定关键词、或是给定正文,可以让模型直接生成出最具有排名优势的文章标题。此外还有关键词分类、关键词竞争程度分析等各式小应用,自然也包括大多人对AI模型唯一熟悉的也即正文生成方面的应用。除了这些直观应用之外,最核心还是在于灵活的运用AI模型能极高效的协助挖掘排序因素——单张3090显卡只需训练几个小时就足以在一部分方面抵上我此前几年的总结。
AI模型刚好是个麻烦的东西,即便不深入底层的数学细节,其它也费力得很。抓取动辄百万计的训练数据、深入显卡原理并购买及租用GPU,又如琢磨模型的实现思路:
先训练评分模型并将之用于后续应用模型的训练,这也是GPT3迈入3.5之中关键的人类偏好对齐过程;
对不同垂直行业的具体生成需求去训练LoRA模型,这也接近于GPT3.5迈入4之中关键的MoE架构的思路;
要么是横跨多领域的知识给推理到硬想出来最佳方案,要么就得去跟进AI业界最前沿的东西。
实际操作时,也会发现对基础的SEO理解有着更大的考验。诸如生成文章标题的应用之中,一开始的训练数据要把标题最大最小字数控制到多少范围?大量过长过短的标题放在训练数据里面,会动辄多耗费几个小时乃至几天的显卡训练时间,而且多少也会对训练效果有损。接下来,又回过头去具体统计多少字数下长尾流量会最大化、多少字数下关键词排名会最靠前。
就如当时统计下来的结论是,至少对于我自己的一个综合问答站而言,大约17~25字的正文title处于长尾流量最大化的区间。而无论是低于这个范围,还是高于这个范围,对其长尾流量的获取能力都会大打折扣。几个字之差就会有几十个百分点的流量劣势,这程度远超出我基于主观经验的估算,于是就开始反思,自己在基础夯实方面其实仍是很不足。
个人解读:zero有自己的综合问答站点,这个应该是seo比较合适的方向?内容解决问题,制作利他网站,解决垂直细分领域的问题,并且更加系统化,阅读方便!-cat网站思考!
我过去多年以来都有一项思考,当然这两年对其思考的会更多些:
假如我精准的丧失了SEO相关的所有记忆,但保留着多年来养成的思考模式,同时,在失忆前我把SEO研究的关键路径也写在了一张纸上,那么,我需要花多长时间来达到此前80%以上的水平?
如今,我认为给我三个月就足够了。只要方向足够明确,这三个月足够我把SEO所必须的基础程度的这些检索原理、程序技术、数据分析、逻辑推理给大概学个明白;接下来实际去探索排序规则,更是只需占其中极少的时间。
这自然不是说SEO就那么一点点东西,而是,当把一系列的知识体系足够程度的抽象化之后,它们应该是会愈发显得简单的。看似截然不同的操作方法背后,往往可以用非常雷同的思路来将之推理出来。假使把一件工作越做越复杂了,我从不认为这是经验丰富的体现,而是认为这代表着极有可能没有抓住那些知识背后真正的本质。
百度的规则很偶尔也会出现特别大的更迭,以致我也曾出现过花了几个月都完全不知道怎么操作的时候。但回顾起来,那浪费的时间,纯属我思考方法陷入了过去经验里面的定式。所以如今我每回进行系统分析时候,本就是要求自己尽可能的放下此前所有的经验,尽可能从零出发。
我总会碰上有些人高谈阔论:这种纯理论能有什么用处?
其一,我做出过的一堆各行业最头部的站,它们当然不是平白无故就能蹦出来的。比如这是如今我自己手头的一个网站:
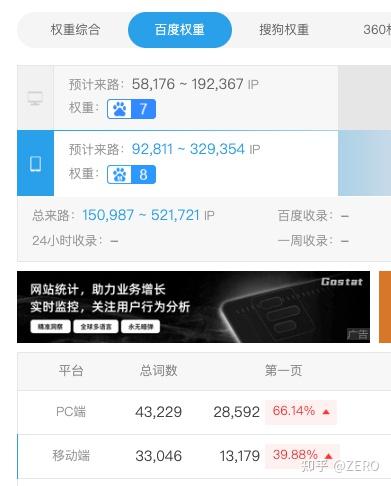
在快排年代有不少爱站第一页词数比例特别高的站,但如今全网40%以上的网站都不到10家,而66%是全网范围内的独一档。还是相当轻松的做到的,我甚至都没为这个网站的优化而去专项再分析全网范围的网站。这网站不太适合公开,且不谈风险主要是公开也没什么收益。但也没什么可藏着掖着的,假若有合作意向的正规站,我都毫不介意给过来看一看。
行业规矩来说很少有人会主动暴露自己网站,因为SEO操作痕迹大部分就在网页上,要是大概懂的人看到了就一目了然。但这对我来说确实没多少影响,本文应该已经挺全面的体现了,我的研究方法和整个SEO业界几乎没任何交集,那操作手段上自然也没交集。就如我在页脚写有「备案」两个字的网站就算放在别人眼前,谁能因此想到这玩意能提升排名?至少我做不到。
(反向推理这事是还有个别同行在做的,但其中最好的也大致在文章中第一例的阶段上还没做到完全成熟——毕竟我一直分析全网所有排名好的网站,逃不过我眼睛)
其二,就如文章提到的几年前在页脚加上「备案」二字就能大幅提升流量,这种个的显然是非常落地的操作,只不过仅当这种规则已经失效以后才便于公开。其它很多我想写的东西,就是不适合写。尤其是如今黑灰产SEO还是不少,他们了解一些操作方法后往往都会极大规模的铺开,过段时间百度就会砍掉对应规则了。
其三,在无人领域探索时,偶尔的突破确实能让人感到很欣喜,但绝大多数时间极为枯燥,也难以很快看到收益,因此其实可能和很多人想象中相反,我压根就不想碰理论研究这种东西。于是只有预期收益足够大的时候才会硬着头皮上——通常是着手大项目,或是百度规则彻底更迭的时候,我整个职业生涯的十余年里面密集的理论研究也就有个四五回。
这两年我有个愈发明确的观点:
人要足够傲慢,否则会被大环境和别人已达到的高度所限,认为自己不可能做到更好,又或认为某个研究方向肯定没法突破,这种自我设限就从根源丧失了所有可能性;
同行们普遍从入行开始就看着各种SEO前辈的经验之谈,却不会在一开始就有所预设——自己有朝一日必定是要把那些前辈踩在脚下的,所以就不该浪费时间去和他们走一样的路。
但人也要足够谦卑,知道自己的能力边界,也意识到客观世界的复杂程度远超自己能力范围,可以随时质疑自己过去无数所想所得全都是错的,否则稍有所成以后很容易进入一个局部最优点,看不到其实在旁边触手可得的更多可能性。
就如也有许多同行因为各式原因而曾做出过巨大的流量效果,他们很普遍的抵触理论研究,声称自己轻轻松松的就能做出流量赚到钱,何必死磕没必要的理论——时间会证明一切,他们无一例外的跟不上百度的变化。既然没有成熟的方法,那如何在规则更迭后还能确保知道新的规则是什么呢?而且最终放弃SEO时候的说辞也颇为一致:都是因为百度太坑了。
个人解读:百度用自己的生态几乎覆盖了所有商业价值的搜索意图,目前看来谷歌无疑是更适合深耕的。
人很难做到既傲慢又谦卑,这大抵就是我既不够聪明更不够努力,却可轻而易举的把SEO做到比别人更好的最关键之处。





